DESCRIPTION · BACKGROUND · MOTIVATION · DATA SOURCE · DATA PROCESSING · EDA · TRAINING · INFERENCE · LIMITATIONS · GITHUB
DESCRIPTION
In this project, I fine tuned RoBERTa using TensorFlow on the CoLA dataset to create a grammatical acceptability classifier. I experimented with both base and large versions, unfreezing different numbers of layers, using CLS token or pooling last hidden states, and hyperparameter tuning, ultimately achieving results on par with the original published paper and further improved performance by experimenting with higher classification thresholds. Data was sourced from the CoLA dataset, and all data cleaning, analysis, and model building were conducted using the Python programming language.
BACKGROUND
This is one part of the final project for the Natural Language Processing class in my Masters in Data Science program. The original project involved three team members including myself, for the showcase here, I have only presented the work I have done, unless noted otherwise. The original project, including the code and the paper can be found here.
In the overall final project, the fine-tuned Grammatical Acceptability Classifier (GAC) model is used in the downstream task to score the input sentences. This project page only focuses on the GAC model, a separate project page is dedicated to the remainder of the overall final project.
The pre-trained RoBERTa model and the tokenizer are sourced from HuggingFace 🤗, but the fine tuning was done manually in Google Colab, with Python as the programming language. Due to the volume of weights in the RoBERTa model, a T4 GPU (that came with the free version of Google Colab) was used during fine-tuning. Notable Python packages used:
- standard: numpy, pandas
- modeling: tensorflow, transformers
- visualization: matplotlib, seaborn
MOTIVATION
As the overall project focuses on error correction of automatic speech recognition transcriptions, we first research on common approaches on grammatical error correction. Numerous papers we read noted that it is beneficial to use a grammatical acceptability classifier to first classify the sentence as grammatical vs ungrammatical first before performing error correction. Inspired by this paper and this paper on grammatical error correction, we decided to fine-tune a pre-trained Large Language Model (LLM) to create the Grammatical Acceptability Classifier (GAC).
Further inspired by the two papers, we decided to use CoLA as our training dataset, given the fact that CoLA was created for the purpose of grammatical NLP tasks, and the data was experted annotated. We contemplated different pre-trained LLMs for the task, our first choice was BERT as it is a commonly used pre-trained LLM, but we ultimated decided on RoBERTa due to the fact that it is largely similar to BERT while outperforming BERT in various benchmarks as result of various improvements employed in the model training process. Similar to most LLMs, the original RoBERTa paper included a fine-tune task for the GLUE benchmark, of which CoLA was one. Our primary goal is then to attempt to beat the CoLA fine-tune task results as presented in the original paper.
DATA SOURCE
We obtained CoLA dataset from the CoLA website. The in_domain train contains 8551 instances of grammatical and ungrammatical sentence, while the in_domain dev contains 527 and the out_domain dev conatains 516 instances respectively. The dataset comes in raw text form as well as tokenized form (tokenized from the NLTK tokenizer), to ensure maximum compatability with the RoBERTa model, we used the raw text and tokenized using RobertaTokenizer instead of directly using the tokenized dataset out of the box.
Below is a sneak peak of the first 5 instances of the in_domain train dataset.
| source | acceptability judgement | sentence |
|---|---|---|
| gj04 | 1 | Our friends won't buy this analysis |
| gj04 | 1 | One more pseudo generalization and I'm giving up. |
| gj04 | 1 | One more pseudo generalization or I'm giving up. |
| gj04 | 1 | The more we study verbs |
| gj04 | 1 | Day by day the facts are getting murkier. |
DATA PROCESSING
Notabily in the original dataset, there is another column for the 'original acceptability judgement as notated by the original author', which is omitted in this view. We did not use that column for our project as 1) the column contained incomplete information, ie, not all sentences contains this notation, and 2) the 'acceptability judgement' column included is reviewed by grammar experts, complete, and can be used to serve as our labels for the training. In processing the data, we also dropped the 'source' column as it is not needed for our training.
EDA
A very simple EDA was performed on the dataset to gauge the distribution of grammatical vs ungrammatical instances in the train, val, and test sets. In both the train and val sets, there are around 70% grammatical instances of all instances, while the test set had around 68% grammatical instances of all instances. This indicates a rather large class imbalance between grammatical vs ungrammatical sentences in the dataset. One potential solution to overcome this class imbalance is to generate more ungrammatical sentences (oversample undersampled class) or to drop excess grammatical sentences (undersample oversampled class). We referred to the original RoBERTa paper and noted that they did not perform additional steps to overcome the class imbalance, to create most comparable results as the original paper, we have also left the data as is.
MODEL PREPARATION
To create comparative results as the original RoBERTa paper, we use the in_domain train for training and in_domain + out_domain dev for test set. The in_domain train is split to training vs validation set at 80% split for training purpose. The original test set is hidden and is not included in this project.
The notebook used for data processing, EDA, and split train, val, & test sets is at: 1.preprocessing/0.Clean_Raw_CoLA_train-val_split.ipynb in GitHub.
For model training and evaluation purpose, however, we used the entire original training set (train + val) for training and the dev set for validation, to match the process done in the original RoBERTa paper. This is not how it should be done as it effectively leaves us with no test data, but we left it as is since we want our results to be comparable to the results presented in the original RoBERTa paper.
TRAINING
A1. Baseline
In our training data, 70% of all instances are grammatical, if one were to assume majority class, then we would achieve accuracy of ~70%. This will serve as the baseline.
All notebooks for the models can be found in the 2.training folder in the GitHub repo.
B1. Training
I started by experimenting with using CLS token vs pooling of Last_Hidden_State as the input to the classification layer.
The CLS token can be extracted by using:
roberta_out = roberta(roberta_inputs)
output_token = roberta_out.last_hidden_state
hidden = output_token[:,0,:]
where as the pooling of Last_Hidden_State can be extracted by using:
roberta_out = roberta(roberta_inputs)
output_token = roberta_out.last_hidden_state
hidden = tf.math.reduce_mean(output_token, axis=1)
The results are omitted in the GitHub repo but the conclusion I drew from the experiments was that classification using pooling of Last_Hidden_State generally outperformed classification using CLS token. This is contradictory to some other results I've see in BERT family models, however, it could be explainable by the fact that the next sentence prediction task was removed in RoBERTa training process, therefore, pooling of the Last_Hidden_State became a better representation than CLS token. Further analysis is needed, but for the purpose of this project, I move on to use exclusively pooling of Last_Hidden_State as the input to the classification layer for all experiments thereafter.
Before I can pass the data into the models, I need to tokenize the data using RobertaTokenizer from transformers library. MAX_LEN is defined to be 512, consistent with the original RoBERTa specification. The same as done for the validation data.
checkpoint = 'roberta-large'
tokenizer = RobertaTokenizer.from_pretrained(checkpoint)
x_train = tokenizer(train['sentence'].tolist(),
add_special_tokens=True,
max_length=MAX_LEN,
padding='max_length',
return_token_type_ids=True,
truncation=True,
return_tensors="tf"
)
y_train = np.array(train['acceptability'].tolist())
I then defined the model by passing in num_unfreeze and hidden_size as parameters, where num_unfreeze will determine the number of layers to unfreeze and hidden_size will determine the size of the classification layer.
for i, each in enumerate(hidden_size):
hidden = tf.keras.layers.Dense(each, activation='relu', name=f'hidden_layer_{i}')(hidden)
hidden = tf.keras.layers.Dropout(0.1)(hidden)
classification = tf.keras.layers.Dense(1, activation='sigmoid',name='classification_layer')(hidden)
The classification model can then be defined by calling tf.keras.Model() and pass in inputs and outputs.
classification_model = tf.keras.Model(inputs=[input_ids, token_type_ids, attention_mask],
outputs=[classification])
Adam Optimizer was used, together with a learning rate schedule, following similar specifications as the original RoBERTa model, as found in this yaml file.
# Optimizer
optimizer = tf.keras.optimizers.Adam(learning_rate=1e-5,
beta_1=0.9,
beta_2=0.98,
epsilon=1e-06,
clipnorm=0.0)
# Learning rate scheduler
lr_schedule = tf.keras.optimizers.schedules.PolynomialDecay(initial_learning_rate=1e-5,
decay_steps=5336,
end_learning_rate=1e-10,
power=1.0)
optimizer.lr = lr_schedule
The model is then compiled with BinaryCrossentropy as the loss function and accuracy as the metric.
classification_model.compile(optimizer=optimizer,
loss=tf.keras.losses.BinaryCrossentropy(from_logits=False),
metrics='accuracy')
For experimentation purpose, I tried unfreezing 0, 3, 6, 12, and 24 layers on RoBERTa-large with batch_size=8. The model weights are saved to disk after each epoch using tf.keras.callbacks.ModelCheckpoint and the training is interrupts once it stops improving. For RoBERTa-base, I only experimented with unfreezing 12 layers, as I expected the model to perform poorly due to the size comparison to RoBERTa-large.
The highest accuracy and MCC on the validation data for each experimented model are listed below. The accuracy and MCC calculated based on 0.5 grammatical threshold.
| model | num_unfreeze | val_accuracy (%) | val_mcc (%) |
|---|---|---|---|
| RoBERTa-Large | 0 | 70.47 | 17.33 |
| RoBERTa-Large | 3 | 83.51 | 59.78 |
| RoBERTa-Large | 6 | 83.80 | 60.52 |
| RoBERTa-Large | 12 | 84.56 | 62.49 |
| RoBERTa-Large | 24 | 87.06 | 68.84 |
| RoBERTa-Base | 12 | 84.28 | 61.77 |
All models beat the baseline of majority class. The model weights for the best performing epoch for each of the above listed models can be accessed at this link.
The best performing model, as highlighted, is, as expected, with RoBERTa-Large and unfreeze all 24 layers. The resulting MCC on the validation set of 68.84 is on-par with the results presented in the RoBERTa paper of 68.0. I then experimented with increasing the grammatical threshold from 0.5 to 0.75, effectively making the model more conservative in its predictions, which increased MCC to 71.10, a 3 point jump. The confusion matrix for the two results are presented as below.
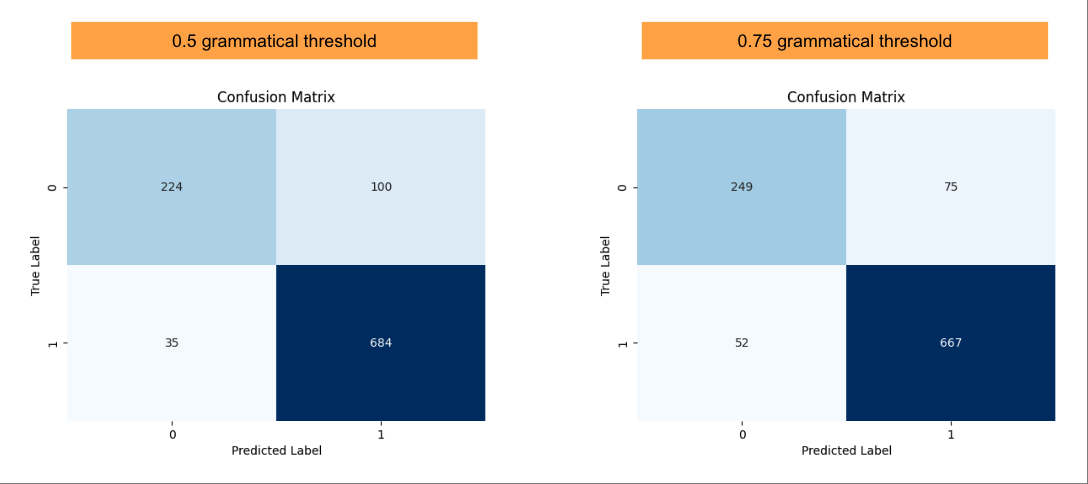
We can see from the confusion matrix that the models classified a good number of sentences correctly, but still there are some instances of misclassification. Below are some examples of misclassification.
FN: True label is acceptable but predicted to be unacceptable.
- The tank leaked the fluid free.
- Most people probably consider, even though the courts didn't actually find, Klaus guilty of murder.
- Mary claimed that eating cabbage, Holly shouldn't.
- Fred talked about everything before Rusty did talk about something.
- Carla slid the book.
- Susan whispered at Rachel.
- John bought a book on the table.
- It is a golden hair.
- It isn't because Sue said anything bad about me that I'm angry.
- With no job would John be happy.
Investigating these examples, it is clear they are indeed difficult sentences that could be mistaken for grammatically incorrect, even for a human.
FP: True label is unacceptable but predicted to be acceptable
- As you eat the most, you want the least.
- The more you would want, the less you would eat.
- The more does Bill smoke, the more Susan hates him.
- Who does John visit Sally because he likes?
- Mickey looked up it.
- The box contained the ball from the tree.
- What the water did to the bottle was fill it.
- What the water did to the whole bottle was fill it.
- Mary beautifully plays the violin.
- Mary intended John to go abroad.
Similar to FNs, it is clear these are also indeed difficult sentences that could be mistaken for grammatically correct, even for a human.
INFERENCE
As the test set is hidden, I did not run the model on the test set. Given the results on the validation set are comparable to the results presented in the original RoBERTa paper, we can reasonably infer the test results will be similar to that of the original paper as well.
For evaluating the model performance on unseen sentences, I wrote a separate blog post where I extracted the grammatical score on some real-life examples using the fine tuned GAC model and discussed the limitation in the model's interpretation of grammar. The blog post also includes a Google Colab notebook that's ready to be run on your own instances in case you want to try you hands on some examples of your own. Be sure to check it out!
LIMITATIONS
As with any models, there are limitations in the Grammatical Acceptability Classifier models presented here as well. In addition to the hyperparameters already mentioned, there are many more hyperparameters that could be tuned to further improve the performance of the model. In addition, due to memory limitation in the free version of Colab, the batch_size was reduced, which could have hindered the model performance. Furthermore, as mentioned previously, the CoLA dataset is unbalanced, which could have also posed limitation to the model performance, which I would like to explore further in future iterations of the project.
GITHUB
Please see my GitHub for the code for the project.